Milvus 是一個開源的向量數據庫,專為管理和檢索大量向量數據而設計,廣泛應用于人工智能、推薦系統、圖像檢索、自然語言處理等領域。它支持 PB 級別的數據存儲,提供高性能的向量檢索服務。
Milvus 的核心功能
1. 高效檢索: 支持 ANN(近似最近鄰)檢索,適用于超大規模向量檢索任務。
2. 多數據類型: 支持文本、圖像、視頻等多種嵌入向量數據。
3. 彈性擴展: 支持水平擴展和分布式部署。
4. 多種索引類型: 包括 IVF、HNSW、DiskANN 等。
5. 多語言 SDK 支持: 提供 Python、Java、Go、C++ 等多種 SDK。
6. 云原生架構: 支持 Kubernetes 部署,便于云上運行。
Milvus 的應用場景
1. 圖像和視頻檢索(內容推薦)
2. 自然語言處理(語義檢索與推薦)
3. 推薦系統(個性化推薦)
4. 生物醫學數據分析(DNA 比對)
5. 安全監控(面部識別)
Milvus 快速上手教程
1. 環境準備
? 操作系統:Linux/macOS/Windows
? 安裝 Docker(推薦)或 Kubernetes(用于生產環境)
2. 安裝 Milvus
使用 Docker 快速啟動:
docker pull milvusdb/milvus:latest
docker run -d –name milvus-standalone -p 19530:19530 -p 8080:8080 milvusdb/milvus:latest
3. 創建 Milvus 客戶端
安裝 Milvus Python SDK:
pip install pymilvus
4. 連接到 Milvus
from pymilvus import connections
connections.connect(
alias=”default”,
host=”localhost”,
port=”19530″
)
5. 創建集合與插入數據
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType
# 定義字段
fields = [
FieldSchema(name=”id”, dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name=”embedding”, dtype=DataType.FLOAT_VECTOR, dim=128)
]
# 定義集合架構
schema = CollectionSchema(fields, “向量數據集合”)
# 創建集合
collection = Collection(“example_collection”, schema)
# 插入數據
import numpy as np
data = [
[i for i in range(1000)], # id
np.random.random([1000, 128]).tolist() # 隨機向量
]
collection.insert(data)
6. 創建索引與檢索
# 創建索引
index_params = {
“metric_type”: “L2”,
“index_type”: “IVF_FLAT”,
“params”: {“nlist”: 100}
}
collection.create_index(field_name=”embedding”, index_params=index_params)
# 搜索向量
search_params = {
“metric_type”: “L2”,
“params”: {“nprobe”: 10}
}
query_vector = np.random.random([1, 128]).tolist()
results = collection.search(
data=query_vector,
anns_field=”embedding”,
param=search_params,
limit=5
)
# 輸出結果
for result in results[0]:
print(f”ID: {result.id}, Distance: {result.distance}”)
Milvus 官方資源
? 官網:Milvus 官方網站
? 文檔:Milvus 文檔中心
? GitHub:Milvus GitHub 倉庫
如果需要更詳細的教程或針對特定場景的使用指導,請告訴我!
]]>1. langdetect
? 簡介: langdetect 是一個非常流行的語言檢測庫,基于 Google 的 language-detection 項目。它可以檢測多種語言,并且對于短文本也有不錯的識別效果。
? 安裝:
pip install langdetect
? 使用示例:
from langdetect import detect
text = “Bonjour tout le monde”
language = detect(text)
print(language) # 輸出: ‘fr’ (法語)
2. langid
? 簡介: langid 是另一個非常強大的語言識別庫,支持97種語言。它的特點是完全自包含且無需外部依賴。
? 安裝:
pip install langid
? 使用示例:
import langid
text = “Hola, ?cómo estás?”
language, _ = langid.classify(text)
print(language) # 輸出: ‘es’ (西班牙語)
3. polyglot
? 簡介: polyglot 是一個支持多語言處理的庫,它不僅提供語言識別功能,還支持情感分析、實體識別等多種自然語言處理任務。
? 安裝:
pip install polyglot
? 使用示例:
from polyglot.detect import Detector
text = “Ceci est un exemple de texte en fran?ais”
detector = Detector(text)
language = detector.language.code
print(language) # 輸出: ‘fr’ (法語)
4. TextBlob
? 簡介: TextBlob 是一個簡潔易用的自然語言處理工具包,雖然它主要用于情感分析、詞性標注等任務,但也支持語言識別。
? 安裝:
pip install textblob
? 使用示例:
from textblob import TextBlob
text = “Hello, how are you?”
blob = TextBlob(text)
print(blob.detect_language()) # 輸出: ‘en’ (英語)

5. FastText (by Facebook)
? 簡介: FastText 是一個由 Facebook 提供的開源庫,除了高效的詞向量表示外,它也能很好地進行語言識別。它支持多達170多種語言。
? 安裝:
pip install fasttext
? 使用示例:
import fasttext
model = fasttext.load_model(‘lid.176.bin’) # 下載預訓練模型
text = “Ceci est un texte en fran?ais”
prediction = model.predict(text)
print(prediction) # 輸出: (‘__label__fr’,)
6. cld3 (Compact Language Detector v3)
? 簡介: cld3 是一個高效的語言檢測庫,基于 Google 的 Compact Language Detector v3。它對短文本和多語言文本都有不錯的支持。
? 安裝:
pip install cld3
? 使用示例:
import cld3
text = “Hola, ?cómo estás?”
language = cld3.get_language(text)
print(language) # 輸出: Language: es (西班牙語)
總結:
? 如果需要一個簡單、易用的工具,langdetect 和 langid 都是不錯的選擇。
? 如果對處理多語言的文本和需要其他 NLP 功能有需求,可以考慮使用 polyglot 或 TextBlob。
? 如果需要更高精度的檢測,尤其是在短文本的情況下,FastText 和 cld3 是更強大的選擇。
你可以根據具體需求選擇適合的工具!
]]>知識共享化:打破信息壁壘
隱性知識大多存在于員工頭腦中,難以規范化。通過自上而下的管理傳遞、員工分享激勵和橫向溝通,企業可有效推動知識共享,避免“沉默的螺旋”和“信息繭房”現象。管理者需通過激勵機制、匿名反饋和互動平臺,激發員工的分享欲望,營造開放的學習環境。
知識顯性化:知識內容清晰易懂
將隱性知識轉化為文檔、視頻等易于理解和傳播的形式。提高知識顯性化水平,需要使用清晰的語言、結構化內容與操作指南,避免“知識的詛咒”,確保員工能夠快速學習與應用。
知識體系化:建立有序知識目錄
通過明確的知識分類與目錄結構,解決信息碎片化和“信息過載”問題。構建企業知識目錄時,需根據業務角色、職能劃分和應用場景細分內容,形成關聯明確、層次清晰的知識網絡,提升員工的信息檢索與學習效率。
知識再生化:激發持續創新
知識的應用與再創造是企業競爭力的源泉。通過精準檢索、實踐操作和創新激勵機制,企業可引導員工不斷學習、應用與改進已有知識,實現知識資產的持續增值。
要實現企業知識管理的四個階段:知識顯性化、知識共享化、知識體系化和知識再生化,推薦以下工具組合,涵蓋文檔管理、協作平臺和學習系統:
1. 知識顯性化(Externalization)工具
將隱性知識轉化為文檔、視頻等形式:
- 文檔與內容管理系統(DMS):如 Microsoft SharePoint、Google Workspace、Notion
- 視頻與演示工具:如 Loom、Camtasia、PowerPoint、Prezi
- 流程與知識捕獲工具:如 Miro(思維導圖)、Lucidchart(流程圖)
2. 知識共享化(Socialization)工具
實現跨團隊知識共享與互動:
- 企業社交平臺與協作工具:如 Microsoft Teams、Slack、Workplace by Meta
- 知識問答與社區平臺:如 Confluence、Yammer、Discourse
- 內部交流與公告平臺:如 Trello、Monday.com(任務與信息公告)
3. 知識體系化(Combination)工具
組織知識、構建有序知識庫:
- 知識庫與文檔管理系統:如 Atlassian Confluence、Notion、Guru
- 搜索與文檔索引工具:如 Elasticsearch、Google Cloud Search、SharePoint Search
- 內容管理與版本控制系統:如 GitHub(適用于技術文檔和代碼管理)
4. 知識再生化(Internalization)工具
學習平臺與持續培訓:
- 學習管理系統(LMS):如 Moodle、TalentLMS、SAP SuccessFactors
- 在線課程與內容平臺:如 Udemy for Business、Coursera for Teams
- 反饋與測評系統:如 SurveyMonkey、Typeform、Google Forms
集成與自動化工具(增強整體效率)
- 自動化工具:如 Zapier、Make(Integromat),將不同系統的數據與任務自動化。
- 企業資源規劃(ERP)系統:如 SAP ERP、Oracle NetSuite,用于集成廣泛業務功能。
]]>
一、為什么需要企業知識目錄?
1. 避免信息過載
- 減少干擾:有效的知識目錄能過濾冗余信息,幫助員工專注于有用數據。
- 增強思維連接:知識目錄能幫助員工更好地理解和記憶新知識,形成清晰的思維框架。
2. 提高學習與決策效率
- 順藤摸瓜:學習內容按照邏輯結構層層展開,便于知識遷移與應用。
- 快速定位信息:通過結構化目錄,員工能快速找到所需資料,避免重復查找。
二、構建企業知識目錄的核心步驟
1. 知識梳理與分類
- 領域劃分:將企業知識按適用角色、業務職能、項目階段等維度劃分。
- 主題細化:細分大類,形成多個子類別。例如,”政策文件”可細分為”申報要求”、”評審標準”等。
2. 知識點關聯與結構化
- 建立層級目錄:
- 從“是什么”開始,再到“為什么”、“如何做”等層次,形成完整的知識鏈。
- 確保目錄邏輯清晰,避免孤立的知識點。
- 交叉關聯:
- 創建知識點之間的引用與鏈接,例如將“項目管理”與“風險控制”相關內容相互引用。
3. 知識標簽與檢索優化
- 標簽體系設計:
- 基于文檔的主題、日期、作者等元數據生成標簽,便于檢索與篩選。
- 搜索引擎集成:
- 引入語義搜索和智能推薦,確保快速、精準的信息定位。
三、企業網盤知識目錄架構設計示例
以下是一個適用于企業網盤的知識目錄架構設計示例:
根目錄:企業知識庫
1. 公司政策與規章制度
- 人事政策
- 財務管理
- 數據安全與合規
2. 項目管理與運營
- 項目文檔
- 項目計劃
- 項目報告
- 風險管理
- 運營流程與標準
3. 產品與服務支持
- 產品手冊
- 技術支持文檔
- 常見問題與解決方案
4. 客戶與市場資料
- 客戶檔案
- 市場調研報告
- 銷售數據與分析
5. 培訓與學習資源
- 內部培訓材料
- 員工技能發展課程
- 行業學習資料
權限與安全控制示例:
- 權限管理:基于用戶角色分配訪問權限。
- 數據備份與恢復:設置自動備份,確保數據安全。
- 使用審計與日志記錄:監控訪問行為,確保合規性。
通過構建系統化的企業知識目錄,企業主不僅能有效應對“信息過載”挑戰,還能激發員工的學習主動性,提升工作效率與決策質量,實現知識資產的最大化利用。
]]>在如今這個信息化的時代,數據對于企業的重要性不言而喻。企業數據不僅是經營決策的依據,也是團隊協作的核心。然而,隨著勒索病毒的肆虐,越來越多企業面臨數據被加密、勒索威脅的困境,企業的運營和發展也因此受到極大威脅。那么,如何有效地防止勒索病毒的侵害呢?一粒云企業網盤系統,為您提供了強大的數據保護能力,讓您的企業數據安全無憂。
1. 防止勒索病毒的“第一道屏障”
勒索病毒之所以如此危險,主要依賴于企業網絡中的共享端口和傳輸協議來傳播。傳統的文件共享方式往往通過SMB(Server Message Block)協議來傳輸數據,這也成為勒索病毒的傳播途徑之一。然而,一粒云企業網盤系統避免了這一隱患,它完全沒有開啟Samba的共享端口,所有的數據傳輸都采用安全的HTTP或HTTPS協議。通過這種方式,企業內部的每一位員工數據都可以通過獨立的客戶端進行備份和共享,確保數據傳輸的安全性,最大限度地降低了勒索病毒通過網絡傳播的風險。
2. 分布式存儲,確保文件安全
勒索病毒往往通過加密文件的后綴來進行勒索,從而威脅企業數據的完整性和可用性。然而,一粒云企業網盤系統采用了先進的分布式存儲技術。每個文件被分散存儲在多個節點上,文件的后綴通常并不會成為勒索病毒的攻擊目標。即使勒索病毒試圖加密或篡改某些文件,也無法輕易對系統中的文件造成破壞。分布式存儲不僅提升了數據的可靠性,還有效避免了勒索病毒的威脅。

3. 獨立的備份與快照機制,輕松恢復數據
即便是再強大的防護措施,也無法百分之百避免所有的勒索病毒攻擊。針對這一點,一粒云企業網盤系統還引入了獨立的文件備份與數據庫快照機制。系統會定期為文件和數據庫創建快照,保存最近30天內的所有數據版本。這意味著,即使企業在某個時刻遭遇勒索病毒攻擊,數據也能通過快照機制迅速回滾,恢復到最近的正常狀態。這樣,企業不僅能夠避免因勒索病毒攻擊而導致的巨大損失,還能夠實現快速的數據恢復,保障業務持續穩定運營。
案例說明:深圳某創新科技公司,四年內兩次遭遇勒索病毒,均成功恢復
讓我們來看一個真實的案例。深圳某創新科技公司在過去四年內,曾兩次遭遇勒索病毒的攻擊,每次都造成了不同程度的數據損失。然而,幸運的是,這家公司使用了一粒云協同文檔云系統。每次病毒攻擊發生后,企業都能通過一粒云的備份和快照機制,迅速恢復丟失的數據,確保了企業運營不受影響。可以說,正是因為一粒云系統強大的數據保護能力,該公司成功避免了勒索病毒帶來的災難性后果。
一粒云,保護數據安全,提高協同效率
對于現代企業來說,數據的安全性至關重要。面對日益猖獗的勒索病毒,一粒云企業網盤系統憑借其創新的技術優勢,提供了全面的防護措施,幫助企業有效避免勒索病毒的侵襲。不僅如此,系統強大的備份與恢復功能,也讓企業在面對數據丟失時能夠迅速恢復,保障了業務的持續性和穩定性。
選擇一粒云,選擇企業數據的安全守護,又是協同的助手。讓我們一起迎接更加安全、更加高效的未來!
]]>1. 工具介紹
? Pymupdf4llm
是基于 PyMuPDF 的輕量級庫,用于解析 PDF 文檔并將其輸出為適合 LLM 使用的格式。主要側重文本提取和結構化處理,適合生成上下文良好的段落,便于用于 LLM 的問答場景。
? pdf-extract-api
是一個基于 API 的工具,專注于從 PDF 中提取特定的數據(如表格、元數據、關鍵段落等)。它通常提供更精細的配置選項,且需要在線服務支持。
2. 優點
Pymupdf4llm
? 開源和輕量化:基于 PyMuPDF,依賴簡單,不需要網絡請求。
? 靈活性:支持本地化部署和定制,適合對隱私敏感的數據處理。
? LLM優化:文本提取經過優化,更適合直接喂給 LLM 使用。
? 社區支持:有 Python 社區的廣泛支持,文檔豐富。
pdf-extract-api
? 精確提取:通過 API 提供強大的功能,如識別表格、圖像提取以及結構化內容分離。
? 便捷性:通常不需要用戶過多了解 PDF 內部結構,適合快速實現提取目標。
? 擴展性:可與其他 API 組合實現復雜任務,如 OCR 集成處理掃描 PDF。
3. 缺點
Pymupdf4llm
? 復雜性有限:對非常復雜的 PDF(如多層嵌套、表格、圖片)支持不如專業化工具。
? 手動調整需求高:對提取后的數據,需要編寫代碼進一步清洗和整理。
pdf-extract-api
? 依賴在線服務:需要網絡訪問,可能對敏感文檔不適合。
? 成本問題:通常是收費服務,使用量大時費用可能較高。
? 上手門檻高:需要了解 API 調用的基礎,復雜設置可能增加學習成本。
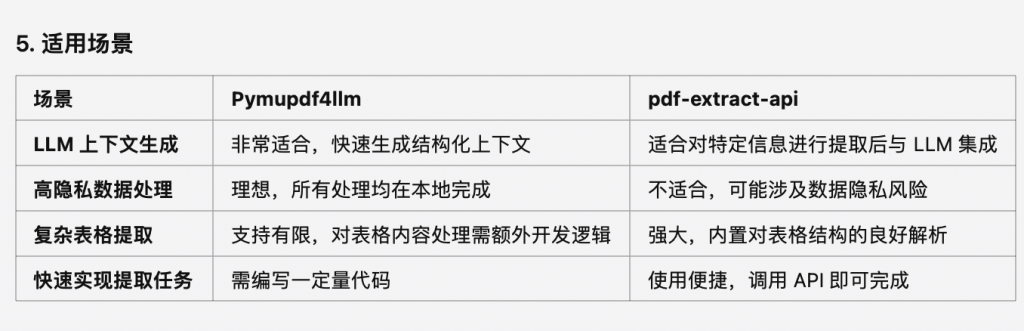
4. 準備度與上手難度
指標 Pymupdf4llm pdf-extract-api
部署與安裝 安裝簡單(pip install pymupdf 等) 需要注冊 API 服務并配置訪問權限
學習曲線 易于上手,Python 開發者友好 需要熟悉 API 文檔,配置參數稍復雜
定制化能力 高,代碼靈活,自由控制輸出內容和格式 中,定制需依賴 API 提供的接口和選項
速度 本地運行,速度快 API 請求受網絡和服務端性能影響
環境依賴 本地運行,無需聯網 需聯網使用在線 API 服務
總結與建議
? 選擇 Pymupdf4llm:
如果你希望完全掌控 PDF 的提取邏輯、對敏感數據有隱私保護需求,并傾向于本地化輕量部署,Pymupdf4llm 是不錯的選擇。
? 選擇 pdf-extract-api:
如果需要快速處理復雜的 PDF 任務(如表格解析、精確提取特定內容),且不介意使用在線服務和支付一定費用,那么 pdf-extract-api 更加適合。
最終選擇取決于項目的復雜性、隱私要求和開發資源。
]]>近日,高德紅外因六名前員工涉嫌盜用公司核心技術,向法院提起了商業秘密侵權訴訟,索賠金額高達2億元人民幣。這一案件不僅讓高德紅外付出了巨大的經濟代價,更警示了所有研發型企業——如何防止企業核心技術和商業秘密的泄露,已經成為了企業面臨的一項重要挑戰。
企業的研發數據、生產技術、設計圖紙等商業秘密一旦泄露,不僅可能導致經濟損失,還可能讓競爭對手迅速獲得市場優勢。在這種背景下,研發型企業必須加強對核心技術的保護,采取先進的數據交換與文件管理技術,防止信息泄露和不法獲取。
高德紅外事件暴露企業數據安全管理的隱患
高德紅外的案例并非個別現象。隨著信息技術的飛速發展,企業內外網隔離的需求不斷增加,但隨之而來的問題也越來越明顯——文件交換和數據傳輸的安全性成為了難題。傳統的U盤、移動硬盤等手動數據交換方式存在多種風險,包括:
- 數據丟失或損壞:U盤和移動硬盤易損壞,數據可能丟失。
- 病毒感染:存儲設備易受病毒攻擊,威脅企業網絡安全。
- 缺乏審計和權限控制:無法精確記錄文件的傳輸路徑,無法追溯數據流轉歷史。
更嚴重的是,在員工離職時,技術泄露的風險大大增加。對于企業來說,如何在內外網隔離的環境下,高效、安全地傳輸核心文件,已成為企業管理中的重要問題。

一粒云KWS隔離網文件安全交換系統:為企業核心技術保駕護航
為了解決這一問題,一粒云KWS隔離網文件安全交換系統應運而生。該系統通過跨網安全擺渡技術,幫助企業實現內外網、多個安全域之間的安全文件流轉,確保敏感數據在傳輸過程中不會泄露。
核心功能:
- 內外網隔離與文件安全交換:通過網閘技術實現內外網的物理隔離和安全交換,文件在交換過程中自動進行病毒查殺、敏感詞過濾和數據加密。
- 智能審批與權限控制:文件交換前,需通過多級審批,確保只有授權人員才能訪問和處理敏感數據。同時,系統支持動態權限管理,防止未授權人員獲取機密信息。
- 實時審計與日志記錄:系統自動記錄所有文件交換的操作日志,所有文件操作都可追溯,確保萬無一失,防止數據泄漏。
- 安全流轉與加密存儲:文件在流轉過程中進行加密存儲,確保即使數據被盜取,也無法被解讀。
一粒云KWS隔離網文件安全交換系統,已經在多個行業和企業中得到了成功應用,為他們提供了全方位的數據安全保障。

企業應用案例:一粒云KWS系統助力多個行業數據安全
- 河北大唐電力:河北大唐電力使用一粒云KWS系統實現了跨區域、跨網絡的文件安全傳輸,確保了各電力生產基地間的數據流轉和工程文件交換不受外部攻擊威脅。該系統的多節點模式使得各分公司間的數據交換更加高效和安全。
- 甘肅大唐電力:甘肅大唐電力通過一粒云系統解決了內部辦公網與外部供應商、合作伙伴之間的文件流轉問題。系統的審批機制確保了所有文件的外發都經過嚴格審查,有效避免了商業秘密泄露的風險。
- 宏工科技:宏工科技是一個高端設備制造商,涉及大量技術研發和產品設計文件。采用一粒云KWS系統后,公司成功地實現了研發數據和生產工藝文件的跨網安全傳輸,并且所有的文件傳輸過程都有詳細的審計記錄,確保商業秘密的安全。
- 金山機器人:金山機器人采用一粒云KWS系統來管理生產數據和技術文檔的交換。通過系統的病毒查殺和敏感詞過濾功能,確保了所有設計圖紙、生產流程文檔在流轉過程中的絕對安全,防止了技術資料的非法外泄。
- 信宇人股份:信宇人股份是一家集研發和生產為一體的高科技企業,通過一粒云KWS系統實現了內外網之間的安全文件交換,成功避免了技術數據外泄的風險。系統的加密存儲和文件審批功能,確保了每一份文件在傳輸過程中都得到充分保護。
早做準備,杜絕高風險事件發生
高德紅外的商業秘密侵權事件再次提醒企業,尤其是那些擁有大量核心技術和敏感數據的研發型企業,在日益復雜的網絡環境中,必須做好充足的防護措施。僅僅依賴傳統的安全策略和手動數據傳輸方式,遠遠不足以應對日益嚴峻的數據泄露風險。
企業應盡早部署像一粒云KWS隔離網文件安全交換系統這樣的高效安全解決方案,實現內外網隔離下的數據傳輸和文件流轉,確保商業秘密不外泄,保護企業的技術創新和核心競爭力。
一粒云KWS隔離網文件安全交換系統不僅能夠為企業提供高效、安全的跨網文件交換解決方案,還能通過智能審批、敏感詞過濾、日志審計等多重功能,確保核心技術和商業秘密在流轉過程中的絕對安全。隨著數據泄露風險的加劇,企業必須早做準備,采取先進的數據交換與管理技術,為核心技術和商業秘密保駕護航。
防患于未然,選擇一粒云,選擇更安全的未來。
]]>客戶為大型企業,采用4個區域隔離的方式形成統一的文檔架構。【 】里面的內容為一粒云 KWS所支持的功能,可以看到我們基本全部滿足的客戶的要求,除了定制功能以外。
- 支持單節點多區域(多空間)部署模式,在不同區域登陸時,僅支持讀取當前區域內的訪問空間,禁止讀取其它區域的內容,防止造成文件傳輸失控。【支持】
- 人員組織信息通過我方的人員信息組織平臺同步,需要文檔擺渡系統這邊開放API接口,我們這邊做對接。【支持,免費提供API】
- 同步的人員信息不包含賬戶信息,無用戶密碼,需要做一個賬戶初次登陸的驗證(驗證形式可以云之家APP掃碼、短信、郵箱等,形式不限),用戶自己設置新密碼,同時可以與組織架構的用戶本人關聯上。【單點登錄,支持Oauth2.0】
- 與ERP平臺的項目信息同步,ERP平臺已開放對應的API接口,需要文檔擺渡平臺主動抓取相關信息,并用于審批流中。【定制開發】
- 審批流的需要滿足兩種維度的支持,一種是依據組織架構的層級進行審批,一種是依據項目維度管理的流程審批,除了申請人的上級需要進行審批外,還需要項目負責人進行審批。【支持】
- 需要支持多層級的壓縮包穿透檢測。【支持】
- 需要支持真實文件的檢測,識別被改的后綴文件的真實文件格式,可以對未知格式、加密壓縮包、無后綴文件進行判斷。【支持】
- DLP審查需要支持常規格式類型文檔的敏感信息檢查,至少要滿足文本文件檢查,有ORC識別、AI學習等功能更好【支持,需要額外購買 AI檢測模塊,支持語意、圖片說明】
- 可根據文檔格式、DLP、病毒的檢查結果,匹配對應的審批流程,可實現直接放行、正常審批、增加審批節點、拒絕、通知相關人員等【流程配置,看需求應該需要定制一些地方】。
- 需支持被億賽通加密的文件進行DLP、病毒檢查,我方可以配合進行加密策略的調整,需要實現加密文件可以被DLP及病毒軟件掃描,在線可預覽,同時確保被傳遞的文件再下載時處于密文狀態。【支持,定制開發在線預覽、調用接口可以完成】
11、在線預覽要有水印功能,可追溯因截屏拍照導致的文件泄露事件。【支持】
12、通知消息需要與云之家APP做集成,通知流程審批節點。【定制對接,推送審批】
13、云之家APP做單點登陸集成,支持在云之家APP端進行流程審批。【定制,對接審批流程模板,綁定到隔離網文件交換的審批流程】
14、支持審批表單的自定義。【支持、目前支持輸入、選擇2種字段、其他的需要定制】
15、支持審批人在PC和手機端在線預覽文件,但不能下載文件。(該功能可根據實際需求進行關閉和開啟)【支持】
16、支持準入功能,非授信的設備無法登陸平臺,或者至少無法下載文件。(其目的是為了防止加密的文件通過平臺進行明文下載,造成加密失控,如果通過其它方式可以確保是密文下載【指定類型文件】,可不用支持準入)【支持,可以綁定設備登錄,非認證設備無法登錄】
17、支持完整的流程日志查詢和審計,便于事件追溯和排查。【支持】
針對這個客戶,我們出具大簡潔方案為:
對接1:單點登錄 【1周】
對接2:賬號組織架構同步【2周】
對接3:對接億賽通加解密、加密、解密、檢查文檔加密狀態【2周】
對接4: DLP 內容檢測后的的流程對接(這里建議綁定 AI內容檢測與我們的文檔安全登分級模塊,根據檢測后的等級進去走對應的流程)【2周】
對接5:自定義審批表單對接或者定制。【1周】
模塊:隔離網文件安全交換審計模塊
系統節點:4個,每個區域一個,提供文檔管理、企業網盤、分布式存儲、文件預覽、權限管理、安全上傳、敏感內容識別等功能。
使用用戶:1200人


1. 教師之間的協作和資源共享
場景: 多個教師需要共享教學資源、教案、課件、試題庫等。
- 問題: 教師之間資源共享不便,文件管理雜亂,版本混亂,導致重復勞動。
- 解決方案: 企業網盤可以為教師提供一個統一的文件存儲和管理平臺,教師可以將教學資源上傳到云端,設置共享權限,確保所有教師都能訪問、編輯和更新最新的教學資料。
- 功能: 文件版本管理、權限設置、協作編輯、搜索功能等,方便資源的快速查找與更新。
2. 學科組長的教學資源整合和管理
場景: 學科組長需要協調并管理本學科所有教師的教學資料,保證教學質量。
- 問題: 文件管理分散、教師上傳的文件格式不一致、版本不統一,難以協調和評審。
- 解決方案: 學科組長可以通過網盤對各類教學文件進行統一管理和規范,設置文件目錄結構,規定文件命名規則,并對上傳的文件進行審核和評估。
- 功能: 集中存儲、文件審批、權限控制,保證文件的統一性和質量。支持分類管理、標準化文檔模板等。
3. 學校領導的文件審批和決策支持
場景: 學校領導需要快速審批各種文件和決策資料,如教學計劃、會議紀要、預算報告等。
- 問題: 文件流轉效率低,審批過程繁瑣,容易出現文件遺失或遺漏。
- 解決方案: 使用網盤系統,學校領導可以在線審批、閱覽和評論文件,確保審批流程的高效性和透明度。同時,網盤可以記錄文件流轉歷史,方便追蹤和管理。
- 功能: 文件審批流程、在線標注與評論、審批記錄追蹤。
4. 跨部門協作與信息共享
場景: 學校各部門之間(如教務處、行政處、后勤部門等)需要共享一些通用文檔,如政策文件、規章制度、校內公告等。
- 問題: 信息溝通不暢,文檔流轉和更新滯后。
- 解決方案: 企業網盤可以作為跨部門的共享平臺,統一存儲學校的公共文檔,確保不同部門能夠實時訪問、更新和修改文件。
- 功能: 跨部門共享、權限管理、協作編輯、多版本支持,確保信息的時效性和完整性。
5. 教師的在線備課與遠程協作
場景: 教師需要在不同地點(例如家里、辦公室、學校外部)進行備課和資料準備,并且需要與其他教師合作進行集體備課。
- 問題: 傳統的備課方式受地點和設備限制,教師難以實時共享和協作。
- 解決方案: 教師可以利用網盤進行云端備課,隨時隨地上傳、下載和修改教學資料,并可以與其他教師進行實時協作編輯。
- 功能: 云端文件存儲、實時協作、遠程訪問、文件同步等,提升教師的備課效率。
6. 教務管理與教學計劃的存檔
場景: 學校教務部門需要保存歷年的教學計劃、課程安排、考試安排等重要文件。
- 問題: 教務文件的存儲、查找和管理不便,歷史文件難以檢索。
- 解決方案: 企業網盤提供長期存檔和搜索功能,所有的教學管理文檔可以按學期、學年等分類進行存儲,方便日后查找與歸檔。
- 功能: 文件歸檔、智能搜索、分類管理、備份恢復,確保文件的安全性和可追溯性。
7. 學校活動和會議記錄管理
場景: 學校領導和教師需要管理學校各類活動的策劃文件、會議記錄、通知等。
- 問題: 文件容易丟失、無法及時查閱,會議記錄等文件多而雜亂,管理困難。
- 解決方案: 使用網盤系統集中存儲所有學校活動相關文件,并支持自動分類和標簽管理。會議記錄和策劃文件可以及時上傳和分享,方便所有相關人員查看。
- 功能: 文件上傳與分享、標簽管理、分類管理、搜索功能,確保文件有序存放,便于查閱。
8. 數據安全與文件備份
場景: 學校對教學資料、學生成績、行政文件等有嚴格的安全要求。
- 問題: 文件存儲在本地或外部設備上存在丟失、損壞等風險。
- 解決方案: 企業網盤可以提供高安全性的云端存儲,定期備份文件,確保數據安全。此外,還能設置訪問權限,避免未經授權的人訪問敏感信息。
- 功能: 數據加密、自動備份、權限控制、文件恢復,保障學校文件數據的安全性和完整性。
總結
企業網盤文檔管理系統可以幫助學校中的不同角色解決很多日常工作中的實際問題。通過集中管理、協作共享、文件審批和在線備課等功能,網盤系統能夠提高工作效率、規范文件管理、加強跨部門協作、保證數據安全,從而為學校的教學和行政工作提供強有力的支持。
]]>RAGFlow 是一個基于對文檔的深入理解的開源 RAG(檢索增強生成)引擎。它為任何規模的企業提供了簡化的 RAG 工作流程,結合了 LLM(大型語言模型)以提供真實的問答功能,并以來自各種復雜格式數據的有根據的引文為后盾。
demo鏈接:RAGFlow
特點:
1、有一定的數據質量保證,能從復雜的非結構化數據中提取基于文檔理解的深度知識。
2、內置模板,可以基于模板形成知識庫;文檔分塊可以實現人工干預,提高文檔質量;
3、可以兼容異構數據源,支持 Word、幻燈片、excel、txt、圖像、掃描副本、結構化數據、網頁等。
4、 自動化且輕松的 RAG 工作流程
- 簡化的 RAG 編排同時滿足了個人和大型企業的需求。
- 可配置的 LLM 以及嵌入模型。
- 多重召回與融合的重新排名配對。
- 直觀的 API,可與業務無縫集成。
RAGFlow架構圖
部署要求:
- CPU >= 4 cores
- RAM >= 16 GB
- Disk >= 50 GB
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
啟動 服務器
- 確保 >= 262144:
vm.max_map_count要檢查 的值 :vm.max_map_count$ sysctl vm.max_map_count如果不是,則重置為至少 262144 的值。vm.max_map_count
- # In this case, we set it to 262144:$ sudo sysctl -w vm.max_map_count=262144此更改將在系統重啟后重置。為了確保您的更改保持永久,請相應地在?/etc/sysctl.conf?中添加或更新該值:
vm.max_map_count - vm.max_map_count=262144
- 克隆存儲庫:$ git clone https://github.com/infiniflow/ragflow.git構建預構建的 Docker 鏡像并啟動服務器:
- 以下命令下載 RAGFlow slim () 的開發版本 Docker 映像。請注意,RAGFlow slim Docker 映像不包括嵌入模型或 Python 庫,因此大小約為 1GB。
dev-slim$ cd ragflow/docker$ docker compose -f docker-compose.yml up -d注意:包含嵌入模型和 Python 庫的 RAGFlow Docker 映像的大小約為 9GB,加載時間可能要長得多。- 要下載特定版本的 RAGFlow slim Docker 鏡像,請將?docker/.env?中的變量更新為所需版本。例如。進行此更改后,請重新運行上述命令以啟動下載。
RAGFlow_IMAGERAGFLOW_IMAGE=infiniflow/ragflow:v0.12.0-slim - 要下載 RAGFlow Docker 映像的開發版本(包括嵌入模型和 Python 庫),請將?docker/.env?中的變量更新為 。進行此更改后,請重新運行上述命令以啟動下載。
RAGFlow_IMAGERAGFLOW_IMAGE=infiniflow/ragflow:dev - 要下載特定版本的 RAGFlow Docker 映像(包括嵌入模型和 Python 庫),請將?docker/.env?中的變量更新為所需的版本。例如。進行此更改后,請重新運行上述命令以啟動下載。
RAGFlow_IMAGERAGFLOW_IMAGE=infiniflow/ragflow:v0.12.0
- 要下載特定版本的 RAGFlow slim Docker 鏡像,請將?docker/.env?中的變量更新為所需版本。例如。進行此更改后,請重新運行上述命令以啟動下載。
- 在服務器啟動并運行后檢查服務器狀態:$ docker logs -f ragflow-server以下輸出確認系統已成功啟動:
- ____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380 INFO:werkzeug:Press CTRL+C to quit如果您跳過此確認步驟并直接登錄 RAGFlow,您的瀏覽器可能會提示錯誤,因為此時您的 RAGFlow 可能沒有完全初始化。network abnormal
- 在您的 Web 瀏覽器中,輸入服務器的 IP 地址并登錄 RAGFlow。使用默認設置時,您只需輸入 (sans?port number) 作為使用默認配置時可以省略默認 HTTP 服務端口。
http://IP_OF_YOUR_MACHINE80 - 在 service_conf.yaml 中,選擇所需的 LLM 工廠,并使用相應的 API 密鑰更新字段。
user_default_llmAPI_KEY有關更多信息,請參閱 llm_api_key_setup。
部署完成后,還需要對RAGFlow進行配置,需要關注以下幾點:
- .env:保留系統的基本設置,例如
SVR_HTTP_PORTMYSQL_PASSWORDMINIO_PASSWORD - service_conf.yaml:配置后端服務。
- docker-compose.yml:系統依賴 docker-compose.yml 啟動。
您必須確保對 .env 文件的更改與 service_conf.yaml 文件中的更改一致。
./docker/README 文件提供了環境設置和服務配置的詳細描述,您需要確保 ./docker/README 文件中列出的所有環境設置都與 service_conf.yaml 文件中的相應配置保持一致。
要更新默認 HTTP 服務端口 (80),請轉到 docker-compose.yml 并更改為 。80:80<YOUR_SERVING_PORT>:80
對上述配置的更新需要重啟所有容器才能生效:
$ docker compose -f docker/docker-compose.yml up -d
 在不嵌入模型的情況下構建 Docker 鏡像
在不嵌入模型的情況下構建 Docker 鏡像
此映像的大小約為 1 GB,依賴于外部 LLM 和嵌入服務。
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/
pip3 install huggingface-hub nltk
python3 download_deps.py
docker build -f Dockerfile.slim -t infiniflow/ragflow:dev-slim .
構建包含嵌入模型的 Docker 鏡像
此映像的大小約為 9 GB。由于它包括嵌入模型,因此它僅依賴于外部 LLM 服務。
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/
pip3 install huggingface-hub nltk
python3 download_deps.py
docker build -f Dockerfile -t infiniflow/ragflow:dev .
 從源頭啟動服務進行開發
從源頭啟動服務進行開發
- 安裝 Poetry,如果已安裝,請跳過此步驟:curl -sSL https://install.python-poetry.org | python3 –
- 克隆源碼并安裝 Python 依賴項:git clone https://github.com/infiniflow/ragflow.git
cd ragflow/
export POETRY_VIRTUALENVS_CREATE=true POETRY_VIRTUALENVS_IN_PROJECT=true
~/.local/bin/poetry install –sync –no-root # install RAGFlow dependent python modules - 使用 Docker Compose 啟動依賴服務(MinIO、Elasticsearch、Redis 和 MySQL):docker compose -f docker/docker-compose-base.yml up -d
- 添加以下行以將?docker/service_conf.yaml?中指定的所有主機解析為:
/etc/hosts127.0.0.1
127.0.0.1 es01 mysql minio redis- 在?docker/service_conf.yaml?中,將 mysql 端口更新為 ,將 es 端口更新為?,如 docker/.env?中指定。
54551200
- 如果無法訪問 HuggingFace,請將環境變量設置為使用鏡像站點:
HF_ENDPOINTexport HF_ENDPOINT=https://hf-mirror.com啟動 backend service: - source .venv/bin/activate
export PYTHONPATH=$(pwd)bash docker/launch_backend_service.sh - 安裝前端依賴項:
- cd webnpm install –force
- 將前端配置為在?.umirc.ts?更新為:
proxy.targethttp://127.0.0.1:9380
啟動前端服務:
npm run dev 以下輸出確認系統已成功啟動完成。
1、Text2KG 的使用
Text2KG是一個開源項目,能夠利用大型語言模型(zero-shot)跨領域從文本中提取實體和關系,自動構建和更新知識圖譜,并通過Neo4j進行可視化。
iText2KG由四個主要模塊組成:文檔提取器、增量實體提取器、增量關系提取器、圖形集成器和可視化。它們協同工作,從非結構化文本構建和可視化知識圖譜。
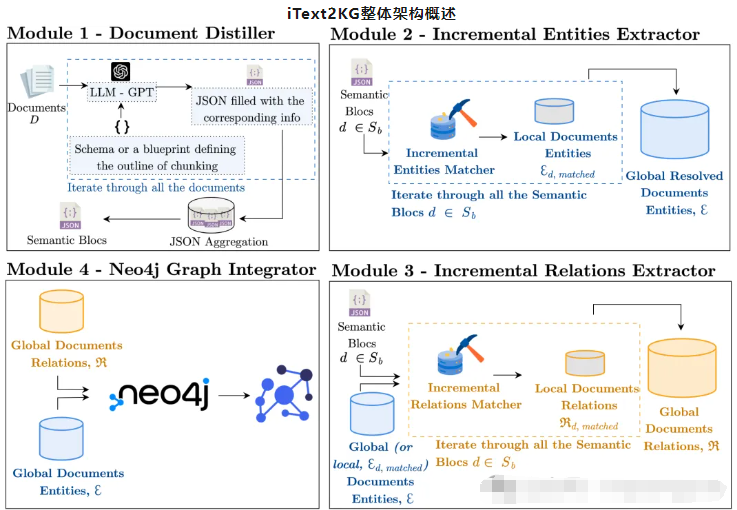
- 文檔提取器(Document Distiller):該模塊處理原始文檔,并根據用戶定義的模式將其重新表述為語義塊。它通過關注相關信息并以預定義的格式對其進行結構化來提高信噪比。
- 增量實體提取器(Incremental Entity Extractor):此模塊從語義塊中提取唯一實體并解決歧義以確保每個實體都有明確定義。它使用余弦相似度度量將局部實體與全局實體進行匹配。
- 增量關系提取器(Incremental Relation Extractor):此模塊識別提取實體之間的關系。它可以以兩種模式運行:使用全局實體豐富圖形中的潛在信息,或使用局部實體建立更精確的關系。
- 圖形集成器和可視化(Graph Integrator and Visualization):此模塊將提取的實體和關系集成到 Neo4j 數據庫中,提供知識圖譜的可視化表示。它允許對結構化數據進行交互式探索和分析。
四個模塊中,增量實體提取器與增量關系提取器最為關鍵,采用大模型來實現,LLM提取代表一個唯一概念的實體,以避免語義混合的實體。顯示了使用 Langchain JSON 解析器的實體和關系提取prompt。分類如下:藍色 – 由 Langchain 自動格式化的prompt;常規 – iText2KG設計的prompt;斜體 – 專門為實體和關系提取設計的prompt。(a)關系提取prompt和(b)實體提取prompt。

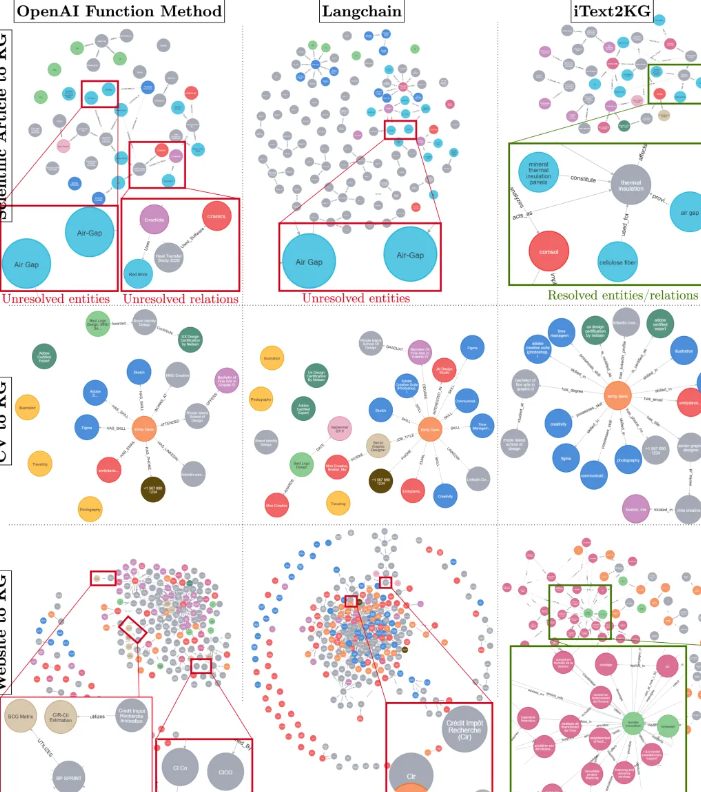
為了說明知識圖譜構建的結果,在三種不同場景下,將基線方法與iText2KG進行了比較:
- 基線方法在所有三種知識圖譜構建場景中都揭示了存在沒有關系的孤立節點。這種現象可能歸因于實體提取和關系提取的同時執行,這可能會在語言模型中引起幻覺效應,導致“遺忘”效應,即分離實體和關系提取的過程可以提高性能。
- 在“網站到知識圖譜”的場景中,輸入文檔數量的增加與圖中噪聲節點的出現有關。這強調了對文檔進行有效精煉和蒸餾的模塊1的關鍵需求。
- iText2KG方法在三種知識圖譜構建場景中展示了改進的實體和關系解析能力。當輸入文檔較少且由簡單、非復雜短語組成時,語言模型在實體和關系解析方面表現出高效率,如“簡歷到知識圖譜”過程中所證明的。相反,隨著數據集變得更加復雜和龐大,挑戰也隨之增加,如“網站到知識圖譜”場景所示。此外,重要的是要強調輸入文檔的分塊大小和閾值對知識圖譜構建的影響。文檔分餾器的輸入文檔可以是獨立的文檔或分塊。如果分塊大小較小,則語義塊將從文檔中捕獲更具體的詳細信息,反之亦然
一種由 LLM 驅動的零樣本方法,使用大型語言模型構建增量知識圖譜(KG)
iText2KG 是一個 Python 包,通過利用大型語言模型從文本文檔中提取實體和關系,逐步構建具有已解析實體和關系的一致知識圖譜。
它具有零樣本能力,無需專門的訓練即可跨各個領域提取知識。
它包含四個模塊:文檔提煉器、增量實體提取器、增量關系提取器和圖形集成器與可視化。
- 文檔提取器:此模塊將原始文檔重新表述為預定義的語義塊,并由指導 LLM 提取特定信息的模式引導。
- 增量實體提取器:此模塊識別并解析語義塊內的唯一語義實體,確保實體之間的清晰度和區別。
- 增量關系提取器:此組件處理已解析的實體以檢測語義上唯一的關系,解決語義重復的挑戰。
Neo4j?圖形集成器:最后一個模塊以圖形格式可視化關系和實體,利用 Neo4j 進行有效表示。
對于我們的 iText2KG 它包含了兩大特點
- 增量構建:
iText2KG?允許增量構建?KG,這意味著它可以在新數據可用時不斷更新和擴展圖,而無需進行大量重新處理。 - 零樣本學習:該框架利用?
LLM?的零樣本功能,使其無需預定義集或外部本體即可運行。這種靈活性使其能夠適應各種?KG?構建場景,而無需進行大量訓練或微調。
一 、設置模型
在運行 iText2KG 之前,我們先設置好大模型,我這里選擇的是 OpenAi 的模型以及 HuggingFace 的 bge-large-zh embedding 模型。這么選擇也是考慮到構建 KG 的準確度。
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "*****"
openai_api_key = os.environ["OPENAI_API_KEY"]
openai_llm_model = llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
messages = [
(
"system",
"You are a helpful assistant that translates English to French. Translate the user sentence.",
),
("human", "I love programming."),
]
ai_msg=openai_llm_model.invoke(messages)開始部署我們的 Embedding 模型:
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
openai_embeddings_model = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
text = "This is a test document."
query_result = openai_embeddings_model.embed_query(text)
query_result[:3]
doc_result = openai_embeddings_model.embed_documents([text])二 、使用 iText2KG 構建 KG
我們這里的場景是,給出一篇簡歷,使用知識圖譜將在線職位描述與生成的簡歷聯系起來。
設定目標是評估候選人是否適合這份工作。
我們可以為 iText2KG 的每個模塊使用不同的 LLM 或嵌入模型。但是,重要的是確保節點和關系嵌入的維度在各個模型之間保持一致。
如果嵌入維度不同,余弦相似度可能難以準確測量向量距離以進行進一步匹配。
我們的簡歷放到根目錄,加載簡歷:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(f"./CV_Emily_Davis.pdf")
pages = loader.load_and_split()初始化 DocumentDistiller 引入 llm :
from itext2kg.documents_distiller import DocumentsDisiller, CV
document_distiller = DocumentsDisiller(llm_model = openai_llm_model)信息提煉:
IE_query = '''
# DIRECTIVES :
- Act like an experienced information extractor.
- You have a chunk of a CV.
- If you do not find the right information, keep its place empty.
'''
# 使用定義好的查詢和輸出數據結構提煉文檔。
distilled_cv = document_distiller.distill(documents=[page.page_content.replace("{", '[').replace("}", "]") for page in pages], IE_query=IE_query, output_data_structure=CV)將提煉后的文檔格式化為語義部分。
semantic_blocks_cv = [f"{key} - {value}".replace("{", "[").replace("}", "]") for key, value in distilled_cv.items() if value !=[] and value != "" and value != None]我們可以自定義輸出數據結構,我們這里定義了4種,工作經歷模型,崗位,技能,證書。
from pydantic import BaseModel, Field
from typing import List, Optional
class JobResponsibility(BaseModel):
description: str = Field(..., description="A specific responsibility in the job role")
class JobQualification(BaseModel):
skill: str = Field(..., description="A required or preferred skill for the job")
class JobCertification(BaseModel):
certification: str = Field(..., description="Required or preferred certifications for the job")
class JobOffer(BaseModel):
job_offer_title: str = Field(..., description="The job title")
company: str = Field(..., description="The name of the company offering the job")
location: str = Field(..., description="The job location (can specify if remote/hybrid)")
job_type: str = Field(..., description="Type of job (e.g., full-time, part-time, contract)")
responsibilities: List[JobResponsibility] = Field(..., description="List of key responsibilities")
qualifications: List[JobQualification] = Field(..., description="List of required or preferred qualifications")
certifications: Optional[List[JobCertification]] = Field(None, description="Required or preferred certifications")
benefits: Optional[List[str]] = Field(None, description="List of job benefits")
experience_required: str = Field(..., description="Required years of experience")
salary_range: Optional[str] = Field(None, description="Salary range for the position")
apply_url: Optional[str] = Field(None, description="URL to apply for the job")定義一個招聘工作需求的描述:
job_offer = """
About the Job Offer
THE FICTITIOUS COMPANY
FICTITIOUS COMPANY is a high-end French fashion brand known for its graphic and poetic style, driven by the values of authenticity and transparency upheld by its creator Simon Porte Jacquemus.
Your Role
Craft visual stories that captivate, inform, and inspire. Transform concepts and ideas into visual representations. As a member of the studio, in collaboration with the designers and under the direction of the Creative Designer, you should be able to take written or spoken ideas and convert them into designs that resonate. You need to have a deep understanding of the brand image and DNA, being able to find the style and layout suited to each project.
Your Missions
Translate creative direction into high-quality silhouettes using Photoshop
Work on a wide range of projects to visualize and develop graphic designs that meet each brief
Work independently as well as in collaboration with the studio team to meet deadlines, potentially handling five or more projects simultaneously
Develop color schemes and renderings in Photoshop, categorized by themes, subjects, etc.
Your Profile
Bachelor’s degree (Bac+3/5) in Graphic Design or Art
3 years of experience in similar roles within a luxury brand's studio
Proficiency in Adobe Suite, including Illustrator, InDesign, Photoshop
Excellent communication and presentation skills
Strong organizational and time management skills to meet deadlines in a fast-paced environment
Good understanding of the design process
Freelance cont繼續使用上面方法做信息提煉:
IE_query = '''
# DIRECTIVES :
- Act like an experienced information extractor.
- You have a chunk of a job offer description.
- If you do not find the right information, keep its place empty.
'''
distilled_Job_Offer = document_distiller.distill(documents=[job_offer], IE_query=IE_query, output_data_structure=JobOffer)
print(distilled_Job_Offer)
semantic_blocks_job_offer = [f"{key} - {value}".replace("{", "[").replace("}", "]") for key, value in distilled_Job_Offer.items() if value !=[] and value != "" and value != None]到這里準備工作完成,簡歷和工作需求都已經提煉完畢,然后正式開始構建 graph,我們將簡歷的所有語義塊作為一個塊傳遞給了 LLM。
也將工作需求作為另一個語義塊傳遞,也可以在構建圖時將語義塊分開。
我們需要注意每個塊中包含多少信息,然后好將它與其他塊連接起來,我們在這里做的就是一次性傳遞所有語義塊。
from itext2kg import iText2KG
itext2kg = iText2KG(llm_model = openai_llm_model, embeddings_model = openai_embeddings_model)
global_ent, global_rel = itext2kg.build_graph(sections=[semantic_blocks_cv], ent_threshold=0.6, rel_threshold=0.6)
global_ent_, global_rel_ = itext2kg.build_graph(sections=[semantic_blocks_job_offer], existing_global_entities = global_ent, existing_global_relationships = global_rel, ent_threshold=0.6, rel_threshold=0.6)iText2KG 構建 KG 的過程我們看到有很多參數,下面分貝是對每個參數的表示做一些解釋:
llm_model:用于從文本中提取實體和關系的語言模型實例。embeddings_model:用于創建提取實體的向量表示的嵌入模型實例。sleep_time (int):遇到速率限制或錯誤時等待的時間(以秒為單位)(僅適用于?OpenAI)。默認為 5 秒。
iText2KG 的 build_graph 參數:
sections?(List[str]):字符串(語義塊)列表,其中每個字符串代表文檔的一部分,將從中提取實體和關系。existing_global_entities?(List[dict], optional):與新提取的實體進行匹配的現有全局實體列表。每個實體都表示為一個字典。existing_global_relationships (List[dict], optional):與新提取的關系匹配的現有全局關系列表。每個關系都表示為一個字典。ent_threshold (float, optional):實體匹配的閾值,用于合并不同部分的實體。默認值為 0.7。rel_threshold (float, optional):關系匹配的閾值,用于合并不同部分的關系。默認值為 0.7。
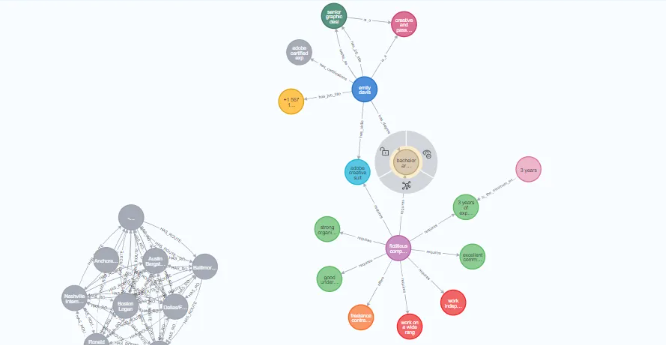
從圖中結果看到我們構建過程中的實體,和關聯關系。
最后使用 GraphIntegrator 對構建的知識圖譜進行可視化。
使用指定的憑據訪問圖形數據庫 Neo4j,并對生成的圖形進行可視化,以提供從文檔中提取的關系和實體的視覺表示。
from itext2kg.graph_integration import GraphIntegrator
URI = "bolt://3.216.93.32:7687"
USERNAME = "neo4j"
PASSWORD = "selection-cosal-cubes"
new_graph = {}
new_graph["nodes"] = global_ent_
new_graph["relationships"] = global_rel_
GraphIntegrator(uri=URI, username=USERNAME, password=PASSWORD).visualize_graph(json_graph=new_graph)打開我們的 Neo4j 圖形數據庫: